
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 자바스크립트
- spring boot
- 어노테이션
- C++
- cache
- 스프링 부트
- Test Coverage
- data structure
- 구버전
- annotation
- Java
- spring
- react
- 하이브리드앱
- AWS
- Deep Learning
- 스프링
- ES6
- 리액트
- 자료구조
- log4j2
- Machine Learning
- kotlin
- javascript
- bean
- JPA
- 제이쿼리
- 테스트 커버리지
- transformer
- jQuery
- Today
- Total
박서희연구소
[Deep Learning] Deep Learning(딥러닝)이 뜨는 이유 본문

Deep Learning의 관심사가 왜 높아졌는지, 그래프를 그리면 쉽게 설명할 수 있다.
가로 축은 어떤 task에 대한 데이터의 양(label이 있는 데이터)을 나타내며, 세로 축은 학습 알고리즘의 성능을 나타낸다.
스팸 메일 분류기, 광고 클릭 수 예상의 정확도, 자율 주행 자동차가 다른 차량의 위치를 파악할 때(Neural Network의 정확도같은)를 예를 들 수 있다.
- Traditional learning algorithm의 성능은 데이터를 추가하는 동안 성능이 향상되지만, 어느정도 지나면 성능이 정체기에 이름(방대한 데이터로 무엇을 해야 할지 모름)
- Neural Network의 규모가 커짐에 따라 훈련시킬 수 록 성능이 좋아짐
- 규모는 Neural Network의 크기, Hidden Unit(은닉 유닛), 연결, 파라미터 수 를 가지는 것과 데이터의 규모를 의미
- 제일 신뢰할 수 있는 성능은 더 큰 Neural Network 훈련과 더 많은 데이터를 집어 넣는 것
- Small training sets 구간에서는 알고리즘의 상대적인 순위가 잘 정의되지 않기 때문에, 데이터가 많지 않다면 구현 방법에 따라 성능이 결정되는 경우가 많음
- 특히, Small training sets 구간에서 더 큰 Neural Network보다 Support Vector Machine이 나을 수 있음
초창기 Deep Learning의 문제는 데이터와 계산의 규모였고, CPU나 GPU에서 아주 큰 Neural Network를 훈련시키게 된 것 만으로도 큰 성과를 낼 수 있었다.
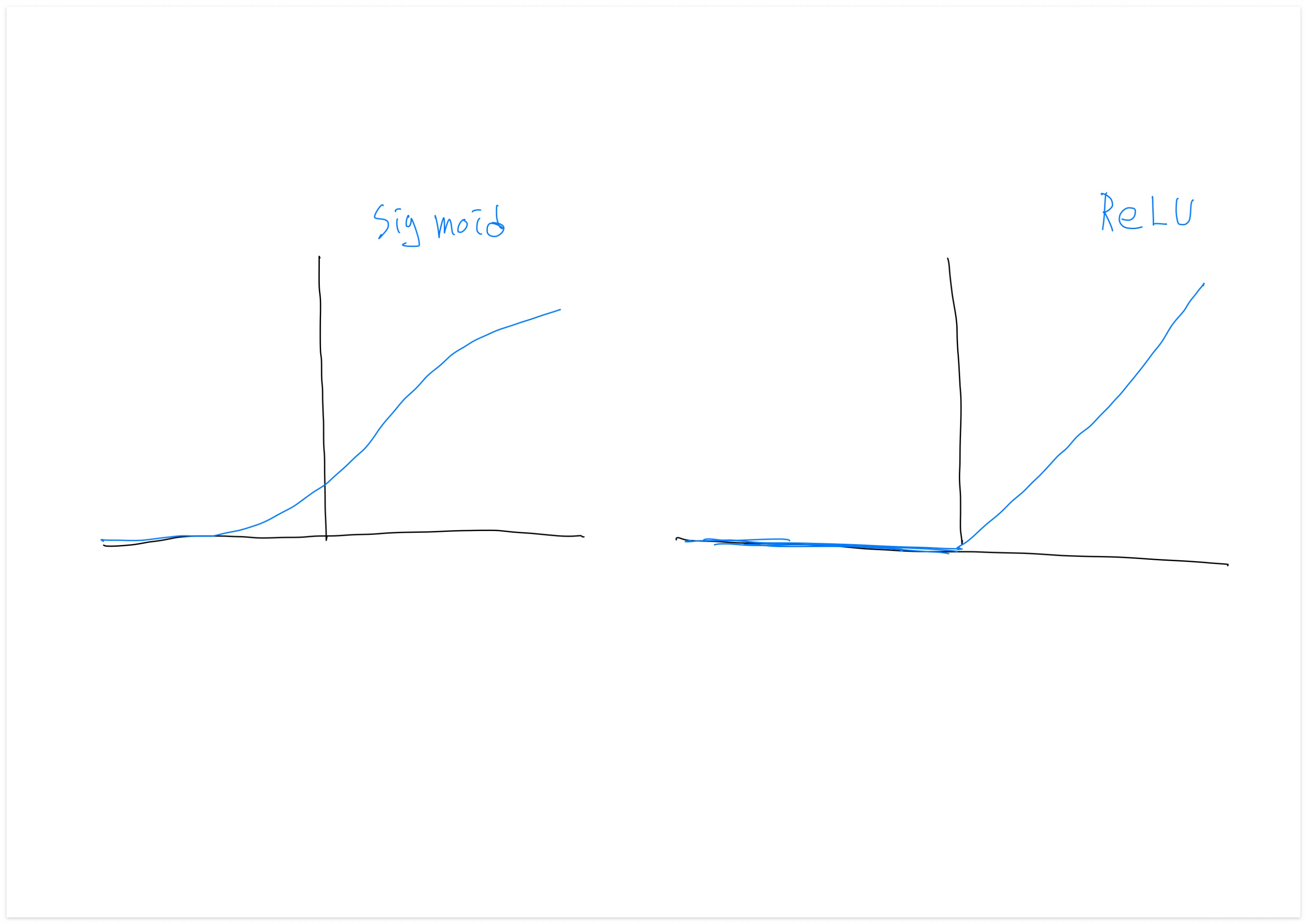
알고리즘 자체로도 큰 혁신으로 기여하였는데(Neural Network을 더 빠르게 실행) Neural Network의 큰 발전의 원인 중 하나로, Sigmoid 함수에서 ReLU 함수로 바뀌게 된 케이스이다.
Machine Learning에서 Sigmoid 함수를 사용하는 데에는 문제가 있다.
함수의 경사가 0인 곳에서 학습이 굉장히 느려지기 때문인데, 경사가 0일 때 경사 하강법을 사용하면 파라미터가 아주 천천히 바뀌고 학습도 느려지기 때문이다.
하지만 ReLU 함수로 바꾸면, 입력값이 양수인 경우 경사가 1로 모두 같으므로 경사가 서서히 0에 수렴할 가능성이 훨씬 적어 경사 하강법 알고리즘은 훨씬 빠르게 만들었다.
빠른 계산이 중요한 이유는 Neural Network을 학습시키는 과정이 아주 반복적이기 때문인데 순서를 보면,
- Neural Network Architecture 설계
- 구현
- 실험
- 수정
위 순서로 진행이 되는데 학습이 오래 걸리면 이 주기도 오래걸리고 생산성의 문제가 생길 수 있다.
- 끝 -
이 내용은 Andrew Ng 교수님의 강의를 수강하고 정리하였음
'○ Programming [AI] > Theory' 카테고리의 다른 글
| [Model] Transformer Model Pipeline(트랜스포머 모델 파이프라인) (0) | 2024.11.26 |
|---|---|
| [Model] Transformer Model(트랜스포머 모델) (0) | 2024.11.22 |
| [Deep Learning] Binary Classification(이진 분류), Logistic Classification(로지스틱 분류) (1) | 2024.02.05 |
| [Deep Learning] Supervised Learning(지도 학습)이란? (0) | 2024.02.01 |
| [Deep Learning] Neural Network(신경망)이란? (0) | 2024.02.01 |

